Every few months, AI research rediscovers the same problem:
Language models break when the world gets big.
Recursive Language Models (RLMs), recently popularized by MIT research, are the latest attempt to address this. They are often framed as a breakthrough in long-context reasoning.
They are not wrong.
But they are also not the real solution.
What RLM actually is
An RLM is not a new model.
It is a way of using an existing LLM recursively.
Instead of stuffing a massive prompt into a single context window, RLM treats the data as an external environment. The model is called repeatedly on small slices, and intermediate results are composed step by step.
In practical terms:
- the model reads a piece
- summarizes or reasons
- decides where to look next
- repeats until an answer emerges
The recursion is operational, not architectural.
This matters, because it tells us what problem RLM is really trying to solve.
The real problem RLM exposes
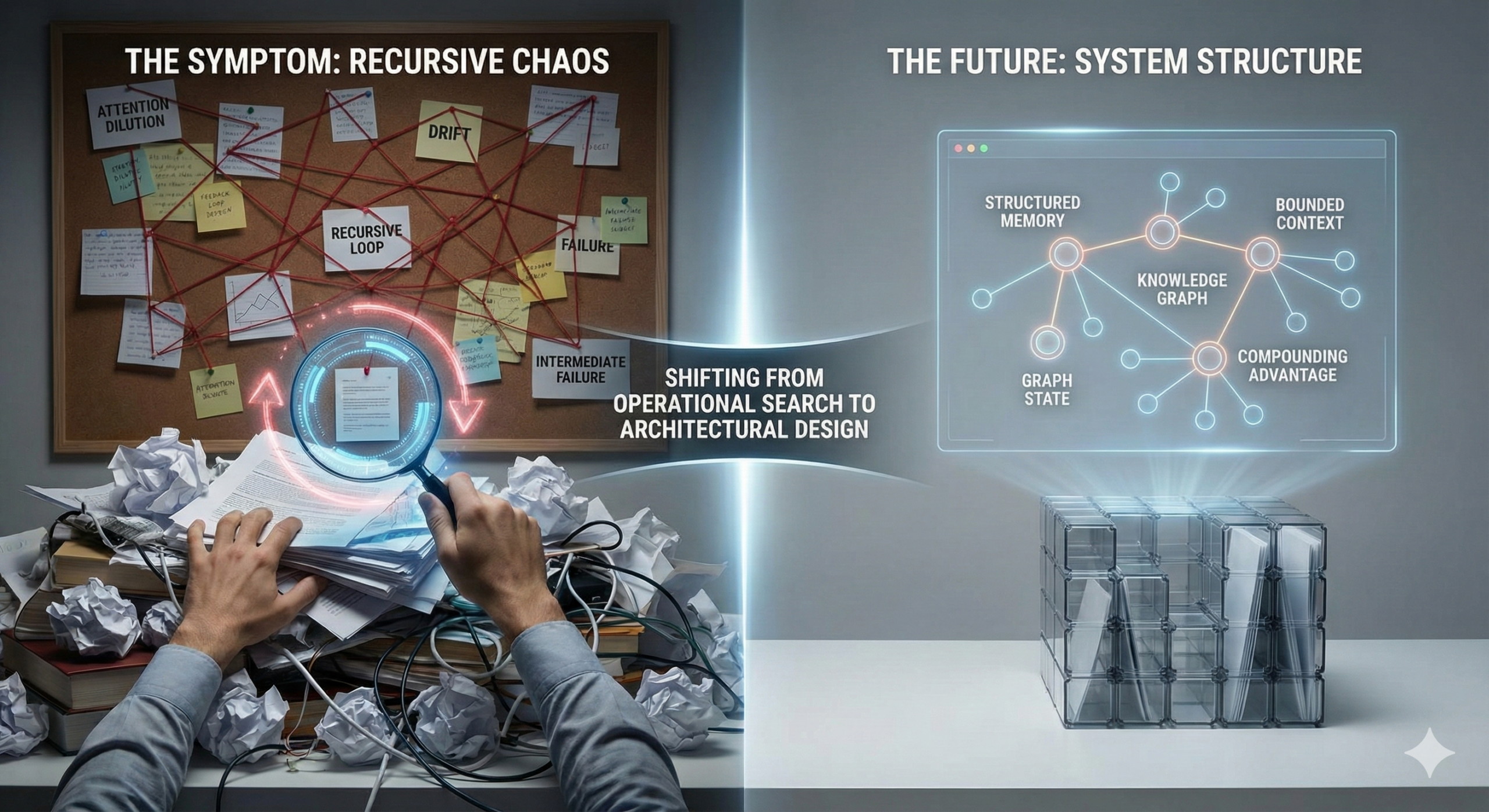
RLM exists because we keep trying to make models do what systems should do.
Long-context reasoning fails not because transformers are “too small,” but because unstructured information does not scale.
When you push millions of tokens into a model, three things happen:
- attention dilutes
- relevance decays
- errors compound silently
RLM is an attempt to regain control by turning inference into a process instead of an event.
That’s the right instinct.
But it is also a workaround.
Why RLM feels powerful
RLM works best when:
- the corpus is massive
- structure is weak or absent
- recall matters more than latency
- human-like exploration is acceptable
Legal discovery. Historical audits. Entire document archives.
In these cases, recursion helps because it replaces brute-force attention with navigation.
The model stops being a reader and becomes a searcher.
That shift is important. But it comes with costs.
The hidden tradeoffs
Recursive systems introduce failure modes that are easy to underestimate.
Control loops drift.
Traversal paths matter.
Intermediate summaries become single points of failure.
Costs grow non-linearly.
Debugging becomes path-dependent instead of input-dependent.
Most importantly, recursion postpones structure.
Instead of designing the system to know what matters, we let the model figure it out repeatedly at runtime.
That is expensive cognition.
The deeper insight RLM points to
RLM is interesting not because recursion is clever, but because it reveals a boundary:
There are two ways to scale reasoning:
- explore more
- structure earlier
RLM chooses exploration.
System design chooses structure.
If you have no structure, recursion is necessary.
If you can create structure, recursion becomes optional.
Why we’re not using RLM (yet)
In the systems I design, the goal is not to help a model “cope” with chaos.
The goal is to remove chaos before inference begins.
That means:
- external memory as state, not text
- graphs instead of piles of documents
- workflows instead of open-ended exploration
- bounded context contracts per step
When structure exists, recursion is wasteful.
You are paying repeatedly to rediscover what the system should already know.
When RLM actually makes sense
I would use RLM only when all of these are true:
- the data is too large to pre-structure safely
- the task requires high recall over raw sources
- correctness matters more than speed
- recursion can be strictly bounded and audited
In other words: rare, high-value, slow tasks.
RLM should be a specialized runtime, not a default architecture.
The broader takeaway
RLM is not the future of language models.
It is evidence that we keep asking models to compensate for missing system design.
As models get stronger, this temptation will increase.
As systems mature, it will disappear.
The long-term advantage will not come from deeper recursion.
It will come from better structure.
And structure, unlike recursion, compounds.